Before we can say anything definitive about the concepts and ideas that we’re studying, it is imperative that we have some understanding about whether the data that we observe and collect are actually “tapping into” the concept of interest.
For example, if my desire were to collect data that are meant to represent how democratic a country is, it would probably not be beneficial to that enterprise to collect measures of annual rainfall. [Though, in some predominantly agricultural countries, that might be an instrument for economic growth.] Presumably, I would want to collect data like whether elections were regularly held, free, and fair, whether the judiciary was independent of elected leaders, etc. That seems quite obvious to most.
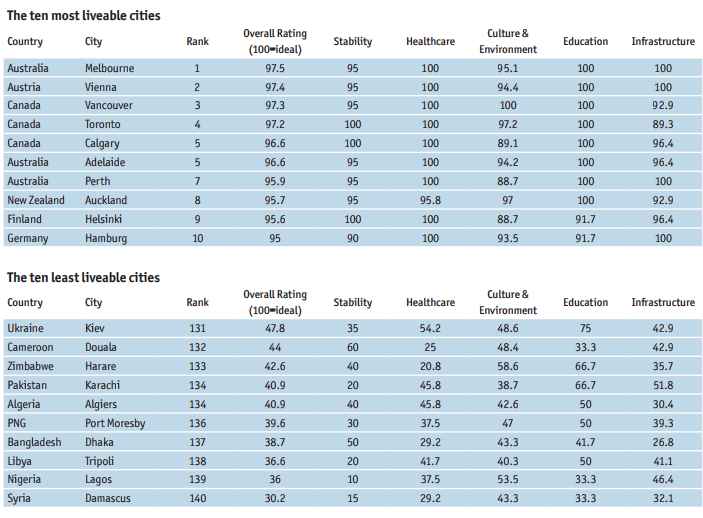
The Economist’s Intelligence Unit puts out an annual “Global Livability Report” , which claims to comparatively assess “livability” in about 140 cities worldwide. The EIU uses many different indicators (across five broad categories) to arrive at a single index value that allegedly reflects the level of livability of each city in the survey. Have a look at the indicators below. Do you notice that the cost-of-living is not include? Why might that be?
This week, we begin to address the politics of climate change. In the chapter from the Stevenson text, the author addresses the rise of two international norms that are related to mitigating the impact of global warming: 1) common but differentiated responsibilities (CBRD) and, 2) mitigation in the form of domestic emissions’ targets.
Stevenson argues that international negotiations regarding mitigation have slowly transitioned from a focus on domestic to global emissions’ targets. Correspondingly, the institutional framework for implementing these goals has moved from regulatory (domestic governments) to market-oriented. China and the United States have been the main promoters (and would also be the main beneficiaries of ) the market-oriented approach to GHG mitigation. We’ll discuss why during this week’s seminar, but in short, high level emitters can use carbon trading schemes to offload their emissions to low-emitting countries, resulting in no drop in emissions of GHGs globally.
In an interesting story on China’s setting up of a domestic carbon market, which is set to begin trading in 2016, we find something interesting. First, here’s a description of the proposed Chines carbon market:
China plans to roll out its national market for carbon permit trading in 2016, an official said Sunday, adding that the government is close to finalising rules for what will be the world’s biggest emissions trading scheme.
The world’s biggest-emitting nation, accounting for nearly 30 percent of global greenhouse gas emissions, plans to use the market to slow its rapid growth in climate-changing emissions.
What caught my eye, however, was the next line:
China has pledged to reduce the amount of carbon it emits per unit of GDP to 40-45 percent below 2005 levels by 2020.
In an informal (convenience sample) survey of some friends and acquaintances, it is obvious that the impression (almost unanimously shared) of the reader was that China would be cutting its GHG emissions dramatically by 2020. Unfortunately, that is not the case.
The key words in the excerpt quoted above are “per unit of GDP.” Because China’s GDP is expected to at least double by 2020 (based on the base year 2005), China could conceivably meet their target of a 40-45-per cent cut in emissions per unit of GDP even with as much as a doubling of actual (absolute) GHG emissions!
In conjunction with this week’s readings on democracy and democratization, here is an informative video of a lecture given by Ellen Lust of Yale University. In her lecture, Professor Lust discuses new research that comparative analyzes the respective obstacles to democratization of Libya, Tunisia, and Egypt. For those of you in my IS240 class, it will demonstrate to you how survey analysis can help scholars find answers to the questions they seek. For those in IS210, this is a useful demonstration in comparing across countries. [If the “start at” command wasn’t successful, you should forward the video to the 9:00 mark; that’s where Lust begins her lecture.]
I have just graded and returned the second lab assignment for my introductory research methods class in International Studies (IS240). The lab required the students to answer questions using the help of the R statistical program (which, you may not know, is every pirate’s favourite statistical program).
The final homework problem asked students to find a question in the World Values Survey (WVS) that tapped into homophobic sentiment and determine which of four countries under study–Canada, Egypt, Italy, Thailand–could be considered to be the most homophobic, based only on that single question.
More than a handful of you used the code below to try and determine how the respondents in each country answered question v38. First, here is a screenshot from the WVS codebook:
Students (rightfully, I think) argued that those who mentioned “Homosexuals” amongst the groups of people they would not want as neighbours can be considered to be more homophobic than those who didn’t mention homosexuals in their responses. (Of course, this may not be the case if there are different levels of social desirability bias across countries.) Moreover, students hypothesized that the higher the proportion of mentions of homosexuals, the more homophobic is that country.
But, when it came time to find these proportions some students made a mistake. Let’s assume that the student wanted to know the proportion of Canadian respondents who mentioned (and didn’t mention) homosexuals as persons they wouldn’t want to have as neighbours.
Here is the code they used (four.df is the data frame name, v38 is the variable in question, and country is the country variable):
Thus, these students concluded that almost 63% of Canadian respondents mentioned homosexuals as persons they did not want to have as neighbours. That’s downright un-neighbourly of us allegedly tolerant Canadians, don’tcha think?. Indeed, when compared with the other two countries (Egyptians weren’t asked this question), Canadians come off as more homophobic than either the Italians or the Thais.
So, is it true that Canadians are really more homophobic than either Italians or Thais? This may be a simple homework assignment but these kinds of mistakes do happen in the real academic world, and fame (and sometimes even fortune–yes, even in academia a precious few can make a relative fortune) is often the result as these seemingly unconventional findings often cause others to notice. There is an inherent publishing bias towards results that seem to run contrary to conventional wisdom (or bias). The finding that Canadians (widely seen as amongst the most tolerant of God’s children) are really quite homophobic (I mean, close to 2/3 of us allegedly don’t want homosexuals, or any LGBT persons, as neighbours) is radical and a researcher touting these findings would be able to locate a willing publisher in no time!
But, what is really going on here? Well, the problem is a single incorrect symbol that changes the findings dramatically. Let’s go back to the code:
The culprit is the | (“or”) character. What these students are asking R to do is to search their data and find the proportion of all responses for which the respondent either mentioned that they wouldn’t want homosexuals as neighbours OR the respondent is from Canada. Oh, oh! They should have used the & symbol instead of the | symbol to get the proportion of Canadian who mentioned homosexuals in v38.
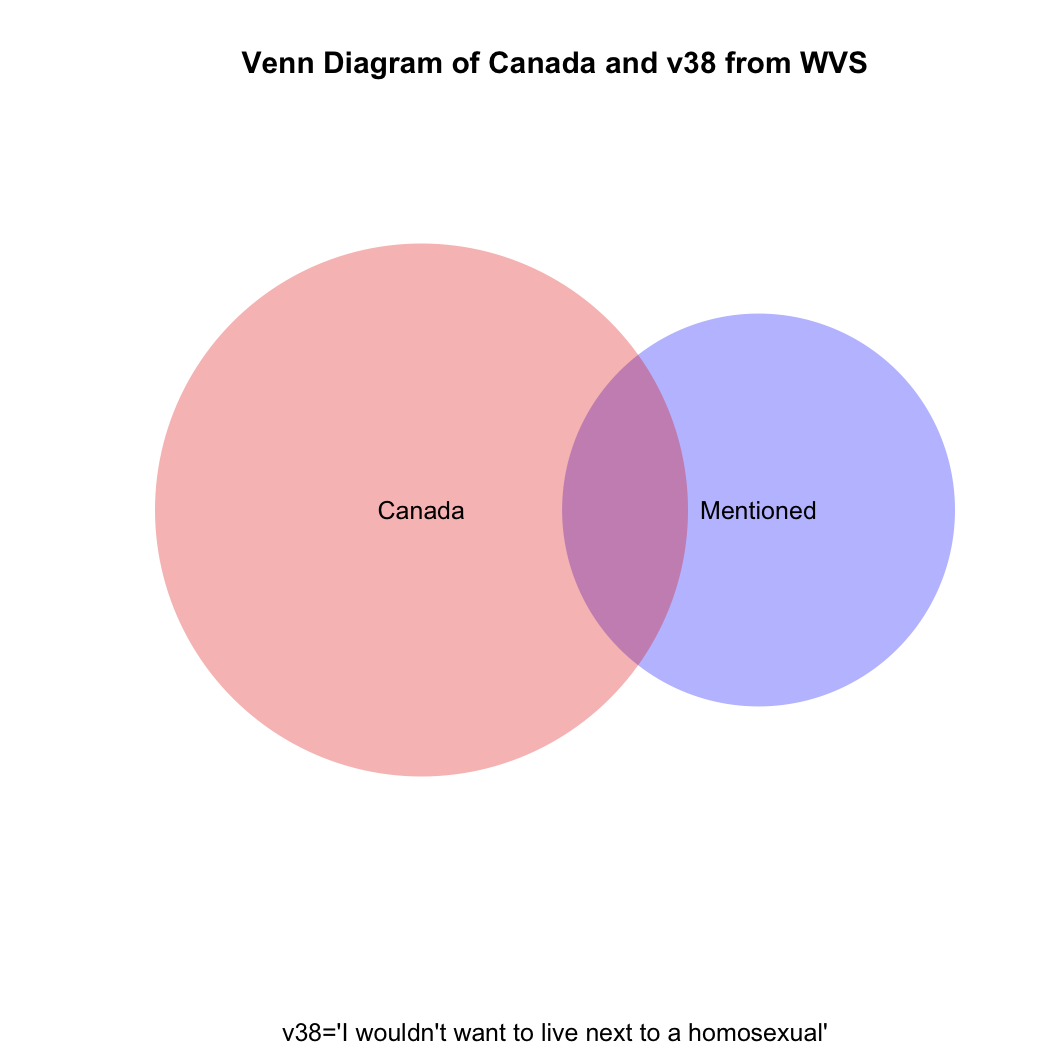
To understand visually what’s happening let’s take a look at the following venn diagram (see the attached video above for Ali G’s clever use of what he calls “zenn” diagrams to find the perfect target market for his “ice cream glove” idea; the code for how to create this diagram in R is at the end of this post). What we want is the intersection of the blue and red areas (the purple area). What the students’ coding has given us is the sum of (all of!) the blue and (all of!) the red areas.
To get the raw number of Canadians who answered “mentioned” to v38 we need the following code:
But what if you then created a proportional table out of this? You still wouldn’t get the correct answer, which should be the proportion that the purple area on the venn diagram comprises of the total red area.
Just eyeballing the venn diagram we can be sure that the proportion of homophobic Canadians is larger than 3.9%. What we need is the proportion of Canadian respondents only(!) who mentioned homosexuals in v38. The code for that is:
prop.table(table(four.df$v38[four.df$v2=="canada"]))
mentioned not mentioned
0.1404806 0.8595194
So, only about 14% of Canadians can be considered to have given a homophobic response, not the 62% our students had calculated. What are the comparative results for Italy and Thailand, respectively?
prop.table(table(four.df$v38[four.df$v2=="italy"]))
mentioned not mentioned
0.235546 0.764454
prop.table(table(four.df$v38[four.df$v2=="thailand"]))
mentioned not mentioned
0.3372781 0.6627219
The moral of the story: if you mistakenly find something in your data that runs against conventional wisdom and it gets published, but someone comes along after publication and demonstrates that you’ve made a mistake, just blame it on a poorly-paid research assistant’s coding mistake.
Here’s a way to do the above using what is called a for loop:
four<-c("canada","egypt","italy","thailand")
for (i in 1:length(four)) {
+ print(prop.table(table(four.df$v38[four.df$v2==four[i]])))
+ print(four[i])
+ }
mentioned not mentioned
0.1404806 0.8595194
[1] "canada"
mentioned not mentioned
[1] "egypt"
mentioned not mentioned
0.235546 0.764454
[1] "italy"
mentioned not mentioned
0.3372781 0.6627219
[1] "thailand"
Here’s the R code to draw the venn diagram above:
install.packages("venneuler")
library(venneuler}
v1<-venneuler(c("Mentioned"=sum(four.df$v38=="mentioned",na.rm=T),"Canada"=sum(four.df$v2=="canada",na.rm=T),"Mentioned&Canada"=sum(four.df$v2=="canada" & four.df$v38=="mentioned",na.rm=T)))
plot(v1,main="Venn Diagram of Canada and v38 from WVS", sub="v38='I wouldn't want to live next to a homosexual'", col=c("blue","red"))
50-foot Jesus statue in front of an abortion clinic
In IS240 on Monday we looked at some of the characteristics of qualitative research methods. such as i) it is inductive, ii) normally interpretivist, and iii) qualitative researchers view constructionist ontological viewpoints. A final characteristic of most qualitative research is that its approach is naturalistic. As the textbook notes:
…qualitative researchers try to minimize the disturbance they cause to the social worlds they study.
We can see the nature of this quality implicitly teased out by Lori Freedman, who discusses some of the research she did for her Master’s degree. Freedman writes about the relationship between abortion and religion (it’s not what you’re expecting) and the time she spent observing in a hospital that performed abortions. Here’s the part related to her research methods:
Claudia [a deeply religious Catholic woman who was having an abortion–JD] told me this story 13 years ago, while I was conducting ethnographic research as a participant-observer in a hospital-based abortion service. I spent considerable time there helping, observing, and intermittently conducting as many interviews as I could with counselors, doctors, and nurses, in order to gain a rich view of abortion clinic life. This study became my master’s thesis, but nothing else. I feared publication might amount to a gratuitous exposé of people I respected dearly. I couldn’t think of any policy or academic imperative that necessitated revealing the intimate dynamics of this particular social world—certainly nothing that could make the potential feelings of betrayal worthwhile. Ultimately, I just tucked it away.
In Chapter 8 of Bryman, Beel, and Teevan, the authors discuss qualitative research methods and how to do qualitative research. In a subsection entitled Alternative Criteria for Evaluating Qualitative Research, the authors reference Lincoln and Guba’s thoughts on how to assess the reliability, validity, and objectivity of qualitative research. Lincoln and Guba argue that these well-known criteria (which developed from the need to evaluate quantitative research) do not transfer well to qualitative research. Instead, they argue for evaluative criteria such as credibility, transferability, and objectivity.
Saharan Caravan Routes–The dotted red lines in the above map are caravan routes connecting the various countries of North Africa including Egypt, Libya, Algeria, Morocco, Mali, Niger and Chad. Many of the main desert pistes and tracks of today were originally camel caravan routes. (What do the green, yellow, and brown represent?)
Transferability is the extent to which qualitative research ‘holds in some other context’ (the quants reading this will immediately realize that this is analogous to the concept of the ‘generalizability of results’ in the quantitative realm). The authors argue that whether qualitative research fulfills this criterion is not a theoretical, but an empirical issue. Moreover, they argue that rather than worrying about transferability, qualitative researchers should produce ‘thick descriptions’ of phenomena. The term thick description is most closely associated with the anthropologist Clifford Geertz (and his work in Bali). Thick description can be defined as:
the detailed accounts of a social setting or people’s experiences that can form the basis for general statements about a culture and its significance (meaning) in people’s lives.
Compare this account (thick description) by Geertz of the caravan trades in Morocco at the turn of the 20th century to how a quantitative researcher may explain the same institution:
In the narrow sense, a zettata (from the Berber TAZETTAT, ‘a small piece of cloth’) is a passage toll, a sum paid to a local power…for protection when crossing localities where he is such a power. But in fact it is, or more properly was, rather more than a mere payment. It was part of a whole complex of moral rituals, customs with the force of law and the weight of sanctity—centering around the guest-host, client-patron, petitioner-petitioned, exile-protector, suppliant-divinity relations—all of which are somehow of a package in rural Morocco. Entering the tribal world physically, the outreaching trader (or at least his agents) had also to enter it culturally.
Despite the vast variety of particular forms through which they manifest themselves, the characteristics of protection in tbe Berber societies of the High and Middle Atlas are clear and constant. Protection is personal, unqualified, explicit, and conceived of as the dressing of one man in the reputation of another. The reputation may be political, moral, spiritual, or even idiosyncratic, or, often enough, all four at once. But the essential transaction is that a man who counts ‘stands up and says’ (quam wa qal, as the classical tag bas it) to those to whom he counts: ‘this man is mine; harm him and you insult me; insult me and you will answer for it.’ Benediction (the famous baraka),hospitality, sanctuary, and safe passage are alike in this: they rest on the perhaps somewhat paradoxical notion that though personal identity is radically individual in both its roots and its expressions, it is not incapable of being stamped onto tbe self of someone else. (Quoted in North (1991) Journal of Economic Perspectives, 5:1 p. 104.
For IS240 next week, (Intro to Research Methods in International Studies) we will be discussing qualitative research methods. We’ll address components of qualitative research and review issues related to reliability and validity and use these as the basis for an in-class activity.
The activity will require students to have viewed the following short video clips, all of which introduce the viewer to contemporary Myanmar. Some of you may know already that Myanmar (Burma) has been transitioning from rule by military dictatorship to democracy. Here are three aspects of Myanmar society and politics. Please watch as we won’t have time in class to watch all three clips. The clips themselves are not long (just over 3,5,and 8 minutes long, respectively).
The first clip shows the impact of heroin on the Kachin people of northern Myanmar:
The next clip is a short interview with a Buddhist monk on social relations in contemporary Myanmar:
The final video clip is of the potential impact (good and bad) of increased international tourism to Myanmar’s most sacred sites, one of which is Bagan.
In a series of recent articles, civil conflict researchers Esteban, Mayoral, and Ray (see this paper for an example) have tried to answer that question. Is it economic inequality, or cultural differences? Or maybe there is a political cause at its root. I encourage you to read the paper and to have a look at the video below. Here are a couple of images from the linked paper, which you’ll see remind you of concepts that we’ve covered in IS210 this semester. The first image is only part of the “Model of Civil Conflict.” Take a look at the paper if you want to see the “punchline.”
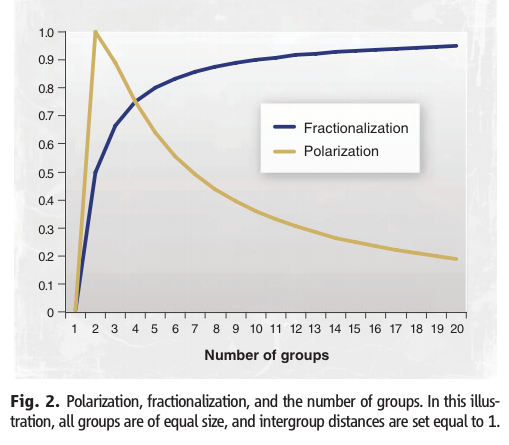
Here is the relationship between fractionalization and polarization. What does each of these measures of diversity measure?
And here’s a nice youtube video wherein the authors explain their theory.
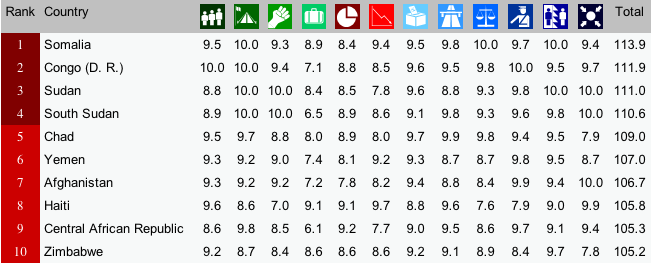
The Failed State Index is created and updated by the Fund for Peace. For the most recent year (2013), the Index finds the same cast of “failed” characters as previous years. There is some movement, the “top” 10 has not changed much over the last few years.
The Top 10 of the Failed States Index for 2013
Notice the columns in the image above. Each of these columns is a different indicator of “state-failedness”. If you go to the link above, you can hover over each of the thumbnails to find out what each indicator measures. For, example, the column with what looks like a 3-member family is the score for “Mounting Demographic Pressures”, etc. What is most interesting about the individual indicator scores is how similar they are for each state. In other words, if you know Country X’s score on Mounting Demographic Pressures, you would be able to predict the scores of the other 11 indicators with high accuracy. How high? We’ll just run a simple regression analysis, which we’ll do in IS240 later this semester.
For now, though, I was curious as to how closely each indicator was correlated with the total score. Rather than run regression analyses, I chose (for now) to simply plot the associations. [To be fair, one would want to plot each indicator not against the total but against the total less that indicator, since each indicator comprises a portion (1/12, I suppose) of the total score. In the end, the general results are similar,if not exactly the same.]
So, what does this look like? See the image below (the R code is provided below, for those of you in IS240 who would like to replicate this.)
Plotting each of the Failed State Index (FSI) Indicators against the Total FSI Score
Here are two questions that you should ponder:
If you didn’t have the resources and had to choose only one indicator as a measure of “failed-stateness”, which indicator would you choose? Which would you definitely not choose?
Would you go to the trouble and expense of collecting all of these indicators? Why or why not?
R-code:
install.packages("gdata") #This package must be installed to import .xls file
library(gdata) #If you find error message--"required package missing", it means that you must install the dependent package as well, using the same procedure.
fsi.df<-read.xls("http://ffp.statesindex.org/library/cfsis1301-fsi-spreadsheet178-public-06a.xls") #importing the data into R, and creating a data frame named fsi.df
pstack.1<-stack(fsi.df[4:15]) #Stacking the indicator variables in a single variable
pstack.df<-data.frame(fsi.df[3],pstack.1) #setting up the data correctly
names(pstack.df)<-c("Total","Score","Indicator") #Changing names of Variables for presentation
install.packages("lattice") #to be able to create lattice plots
library(lattice) #to load the lattice package
xyplot(pstack.df$Total~pstack.df$Score|pstack.df$Indicator, groups=pstack.df$Indicator, layout=c(4,3),xlab="FSI Individual Indicator Score", ylab="FSI Index Total")
That’s quite a comprehensive title to this post, isn’t it? A more serious social scientist would have prefaced the title with some cryptic phrase ending with a colon, and then added the information-possessing title. So, why don’t I do that. What about “Nibbling on Figs in an Octopus’ Garden: Explanation, Statistics, GDP, Democracy, and the Social Progress Index?” That sounds social ‘sciencey’ enough, I think.
Now, to get to the point of this post: one of the most important research topics in international studies is human welfare, or well-being. Before we can compare human welfare cross-nationally, we have to begin with a definition (which will guide the data-collecting process). What is human welfare? There is obviously some global consensus as to what that means, but there are differences of opinion as to how exactly human welfare should be measured. (In IS210, we’ll examine these issues right after the reading break.) For much of the last seven decades or so, social scientists have used economic data (particularly Gross Domestic Product (GDP) per capita as a measure of a country’s overall level of human welfare. But GDP measures have been supplemented by other factors over the years with the view that they leave out important components of human welfare. The UN’s Human Development Index is a noteworthy example. A more recent contribution to this endeavour is the Social Progress Index (SPI) produced by the Social Progress Imperative.
HDI–Map of the World (2013)
How much better, though, are these measures than GDP alone? Wait until my next post for answer. But, in the meantime, we’ll look at how “different” the HDI and the SPI are. First, what are the components of the HDI?
“The Human Development Index (HDI) measures the average achievements in a country in three basic dimensions of human development: a long and healthy life, access to knowledge and a decent standard of living.”
So, you can see that it goes beyond simple GDP, but don’t you have the sense that many of the indicators–such as a long and healthy life–are associated with GDP? And there’s the problem of endogeneity–what causes what?
The SPI is a recent attempt to look at human welfare even more comprehensively, Here is a screenshot showing the various components of that index:
We can see that there are some components–personal rights, equity and inclusion, access to basic knowledge, etc.,–that are absent from the HDI. Is this a better measure of human well-being than the HDI, or GDP alone? What do you think?










You must be logged in to post a comment.