In data visualization posts #21 and #22, I referred to the results of simple multivariate linear regressions where I examined the statistical relationships between the cost of electricity across European Union countries and the market penetration of renewable energy sources, and a cost-of-living index. Here are the regression results that form the source data for the predictive plots in those blog posts.
First, with the price of electricity as the dependent variable (DV):
## Here is the R code for the linear regression (using the generalized linear models (glm) framework:
glm.1<-glm(Elec_Price~COL_Index+Pct_Share_Total,data=eu.RENEW.only,family="gaussian") # Electricity Price is DV
MODEL INFO:
Observations: 28
Dependent Variable: Price of Household Electricity (in Euro cents)
Type: Linear regression
MODEL FIT:
χ²(2) = 306.82, p = 0.00
Pseudo-R² (Cragg-Uhler) = 0.40
Pseudo-R² (McFadden) = 0.08
AIC = 166.04, BIC = 171.37
Standard errors: MLE
-------------------------------------------------------------
Est. S.E. t val. p
------------------------------ ------ ------ -------- ------
(Intercept) 4.10 3.59 1.14 0.26
Cost-of-Living Index 0.22 0.06 3.59 0.00
Renewables (% share of total) 0.03 0.04 0.74 0.46
-------------------------------------------------------------
We can see that the cost-of-living index is positively correlated with the price of household electricity, and it is statistically significant at conventional (p=0.05) levels. The market penetration of renewables (on the other hand) is not statistically significant (once controlling for cost-of-living.
Now, we use the pre-tax price of electricity (there are large differences in levels of taxation of household electricity across EU countries) as the DV. Here are the regression code (R) and the model results of the multivariate linear regression.
## Here is the R code for the linear regression (using the generalized linear models (glm) framework:
glm.2<-glm(Elec_Price_NoTax~COL_Index+Pct_Share_Total,data=eu.RENEW.only,family="gaussian") # Elec Price LESS taxes/levies is DV
MODEL INFO:
Observations: 28
Dependent Variable: Pre-tax price of Household Electricity (Euro cents)
Type: Linear regression
MODEL FIT:
χ²(2) = 100.13, p = 0.00
Pseudo-R² (Cragg-Uhler) = 0.44
Pseudo-R² (McFadden) = 0.12
AIC = 130.11, BIC = 135.43
Standard errors: MLE
-------------------------------------------------------------
Est. S.E. t val. p
----------------------------- ------- ------ -------- ------
(Intercept) 5.20 1.89 2.75 0.01
Cost-of-Living Index 0.14 0.03 4.41 0.00
Renewables (% share of total) -0.03 0.02 -1.44 0.16
-------------------------------------------------------------
Here, we see an even stronger relationship between the cost-of-living and the pre-tax price of household electricity, while there is (once the cost-of-living is controlled for) a negative (though not quite statistically significant) relationship between the pre-tax cost of electricity and the market penetration of renewables across EU countries.
In post #21 of this series, I examined the relationship between electricity prices across European Union (EU) countries and the market penetration of renewable (solar and wind) energy sources. There’s been some discussion amongst the defenders of the continued uninterrupted burning of fossil fuels of a finding that allegedly shows the higher the market penetration of renewables, the higher electricity prices. I demonstrated in the previous post that this is a spurious relationship and a more plausible reason for the empirical relationship is that market penetration is highly correlated with how rich (and expensive) a country is. Indeed, I showed that controlling for cost-of-living in a particular country, the relationship between market penetration of renewables and cost of electricity was not statistically significant.
I noted at the end of that post that I would show the results of a simple multiple linear regression of the before-tax price of electricity and market penetration of renewables across these countries.
But, first here is a chart of the results of the predicted price of before-tax electricity in a country given the cost-of-living, holding the market penetration of renewables constant. We see a strong positive relationship—the higher the cost-of-living in a country, the more expensive the before-tax cost of electricity.
Created by: Josip Dasović
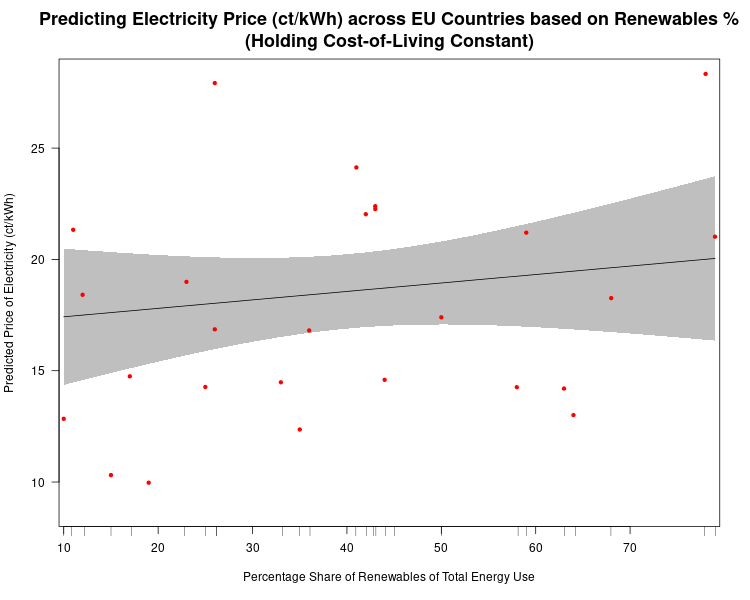
Here’s the chart based on the results of a multiple regression analysis using before-tax electricity price as the dependent variable, with renewables market penetration as the main dependent variable, holding the cost-of-living constant. The relationship is obviously negative, but it is not statistically significant. Still, there is NOT a positive relationship between the market penetration of renewables and the before-tax price of electricity across EU countries.
One of the first things that is (or should be) taught in a quantitative methods course is that “correlation is not causation.” That is, just because we establish that a correlation between two numeric variables exists, that doesn’t mean that one of these variables in causing the other, or vice versa. And to step back ever further in our analytical process, even when we find a correlation between two numerical variables, that correlation may not be “real.” That is, it may be spurious (caused by some third variable) or an anomaly of random processes.
I’ve seen the chart below (in one form or another) for many years now and it’s been used by opponents of renewable energy to support their argument that renewable energy sources are poor substitutes for other sources (such as fossil fuels) because, amongst other things, they are more expensive for households.
In this example, the creators of the chart seem to show that there is a positive (and non-linear) relationship between the percentage of a European country’s energy that is supplied by renewables and the household price of electricity in that country. In short, the more a country’s energy grid relies on renewables, the more expensive it is for households to purchase electricity. And, of course, we are supposed to conclude that we should eschew renewables if we want cheap energy. But is this true?
No. To reiterate, a bivariate (two variables) relationship is not only not conclusive evidence of a statistical relationship truly existing between these variables, but we don’t have enough evidence to support the implied causal story–more renewbles equals higher electricity prices.
Even a casual glance at the chart above shows that countries with higher electricity prices are also countries where the standard (and thus, cost) of living is higher. Lower cost-of-living countries seem to have lower electricity prices. So, how do we adjudicate? How do we determine which variables–cost-of-living, or renewables penetration–is actually the culprit for increased electricity prices?
In statistics, we have a tool called multiple regression analysis. It is a numerical method, in which competing variables “fight it out” to see which has more impact (numerically) on the variation in the dependent (in this case, cost of electricity) variable. I won’t get into the details of how this works, as it’s complicated. But it is a standard statistical method.
So, what do we notice when we perform a multivariate linear regression analysis (note: a non-linear method actually strongly the case below even more strongly, but we’ll stick to linear regression for ease of interpretation and analysis) where we “control for” each of the two independent variables–cost-of-living and renewables penetration)?
The image below shows (contrary to the implied claim in the chart above) that once we a country’s cost of living, there is little influence on the price of household electricity of renewables penetration in a country Moreover, the impact is not “statistically significant (see table at the end of the post).” That is, based on the data it is highly likely that the weak relationship we do see is simply due to random chance. We see this weak relationship in the chart below, which is the predicted cost of electricity in each country based on different levels of renewables penetration, holding the cost-of-living constant.
Created by: Josip Dasović
At only 10% of renewable penetration in a country the predicted price of electricity is about 17.5 ct/kWh (the shaded grey areas are 95% confidence bands, so we see that even though our best estimate of the price of electricity for a country that gets only 10% of its energy from renewables is 17.5 ct/kWh, we would expect the actual result to be between 14.5 ct/kWh and 20.5 ct/kWh 95% of the time. Our best estimate of the predicted cost of electricity in a country that gets 80% of its energy from renewables is expected to be about 19.5 ct/kWh. So, an 800% increase in renewables penetration leads only to only a 14.5% increase in the predicted price of electricity.
Now, what if we plot the predicted price of household electricity based on the cost-of-living after controlling for renewables penetration in a country? We see that, in this case, there is a much stronger relationship, which is statistically significant (highly unlikely for these data to produce this result randomly).
There are two things to note in the chart above. First, the 95% confidence bands are much closer together indicating much more certainty that there is a true statistical relationship between the “Cost-of-Living Index (COL)” and the predicted price of household electricity. And, we see that a 100% increase in the COL leads to a ((15.5-9.3)/9.3)*100%, or 67% increase in the predicted price of electricity in any EU country. (Note: I haven’t addressed the fact that electricity prices are a component of the COL, but they are so insignificant as to not undermine the results found here.
Stay tuned for the next post, where I’ll show that once we take out taxes and levies the relationship between the predicted price of household electricity and the penetration of renewables in an EU country is actually negative.
Here is the R code for the regression analyses, the prediction plots, and the table of regression results.
## This is the linear regression.
reg1<-lm(Elec_Price~COL_Index+Pct_Share_Total,data=eu.RENEW.only)
library(stargazer) # needed for prediction cplots
## Here is the code for the two prediction plots.
## First plot
cplot(reg1,"COL_Index", what="prediction", main="Cost-of-Living Predicts Electricity Price (ct/kWh) across EU Countries\n(Holding Share of Renewables Constant)", ylab="Predicted Price of Electricity (ct/kWh)", xlab="Cost-of-Living Index")
## Second plot
cplot(reg1,"Pct_Share_Total", what="prediction", main="Share of Renewables doesn't Predict Electricity Price (ct/kWh) across EU Countries\n(Holding Cost-of-Living Constant)", ylab="Predicted Price of Electricity (ct/kWh)", xlab="Percentage Share of Renewables of Total Energy Use")
The table below was created in LaTeX using the fantastic stargazer (v.5.2.2) package created for R by Marek Hlavac, Harvard University. E-mail: hlavac at fas.harvard.edu
In teaching research methods courses in the past, a tool that I’ve used to help students understand the nuances of policy analysis is to ask them to assess a claim such as:
In the last 12 months, statistics show that the government of Upper Slovobia’s policy measures have contributed to limiting the infollcillation of ramakidine to 34%.
The point of this exercise is two-fold: 1) to teach them that the concepts we use in social science are almost always socially constructed, and we should first understand the concept—how it is defined, measured, and used—before moving on to the next step of policy analysis. When the concepts used—in this case, infollcillation and ramakidine—are ones nobody has every heard of (because I invented them), step 1 becomes obvious. How are we to assess whether a policy was responsible for something when we have zero idea what that something even means? Often, though, because the concept is a familar one—homelessness, polarization, violence—we often skip right past this step and focus on the next step (assessing the data).
2) The second point of the exercise is to help students understand that assessing the data (in this case, the 34% number) can not be done adequately without context. Is 34% an outcome that was expected? How does that number compare to previous years and the situation under previous governments, or the situation with similar governments in neighbouring countries? (The final step in the policy analysis would be to set up an adequate research design that would determine the extent to which the outcome was attributable to policies implemented by the South Slovobian government.)
If there is a “takeaway” message from the above, it is that whenever one hears a numerical claim being made, first ask yourself questions about the claim that fill in the context, and only then proceed to evaluate the claim.
Let’s have a look at how this works, using a real-life example. During a recent episode of Real Time, host Bill Maher used his New Rules segment to admonish the public (especially its more left-wing members) for overestimating the danger to US society of the COVID-19 virus. He punctuated his point by using the following statistical claim:
Maher not only claims that the statistical fact that 78% of COVID-19-caused fatalities in the USA have been from those who were assessed to have been “overweight” means that the virus is not nearly as dangerous to the general USA public as has been portrayed, but he also believes that political correctness run amok is the reason that raising this issue (which Americans are dying, and why) in public is verboten. We’ll leave aside the latter claim and focus on the statistic—78% of those who died from COVID-19 were overweight.
Does the fact that more than 3-in-4 COVID-19 deaths in the USA were individuals assessed to have been overweight mean that the danger to the general public from the virus has been overhyped? Maher wants you to believe that the answer to this question is an emphatic ‘yes!’ But is it?
Whenever you are presented with such a claim follow the steps above. In this case, that means 1) understand what is meant by “overweight” and 2) compare the statistical claim to some sort of baseline.
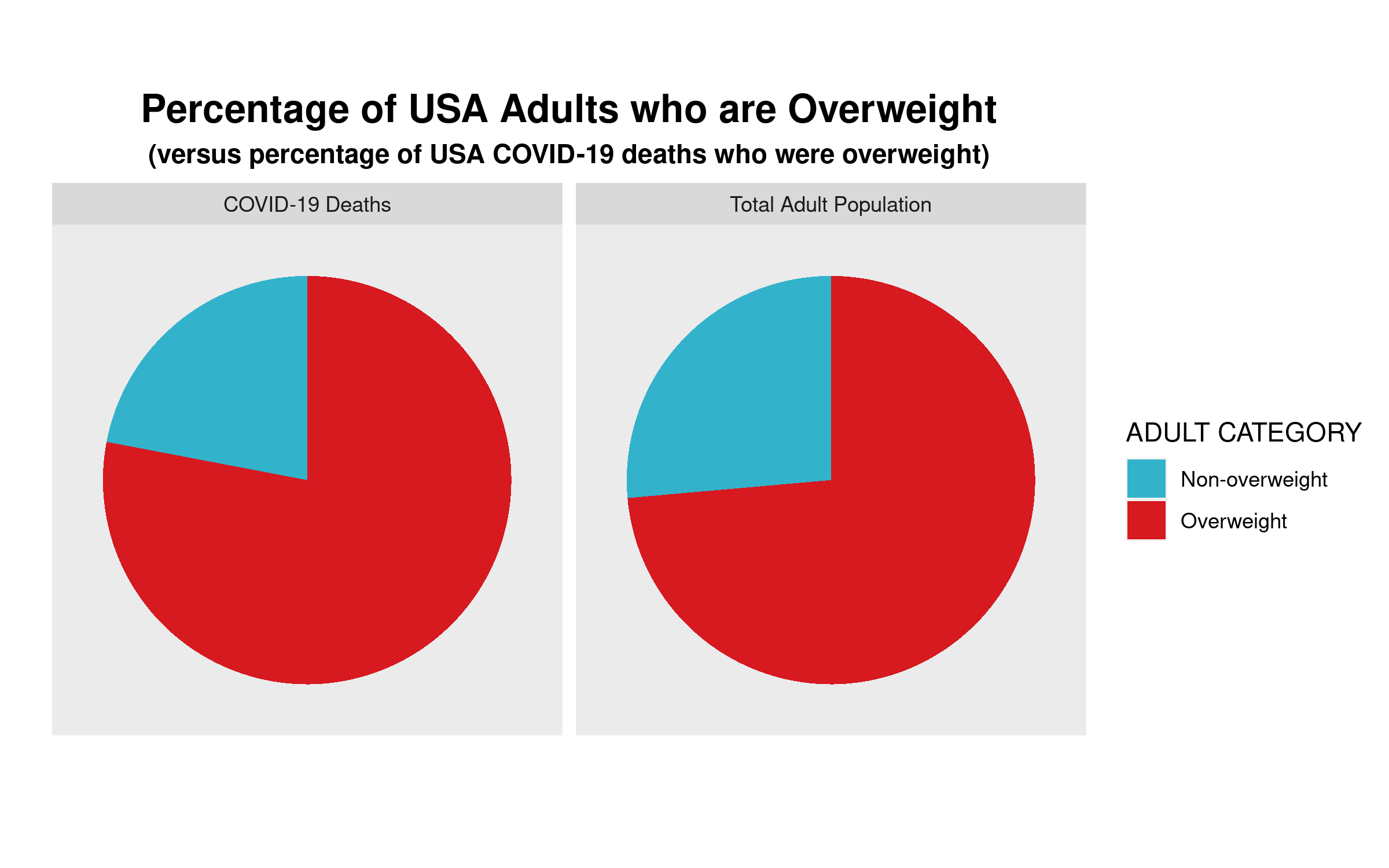
The first is relatively easy—the US CDC has a standard definition for “overweight”, which can be found here: https://www.cdc.gov/obesity/adult/defining.html. Assuming that the definition is applied consistently across the whole of the USA, we can move on to step 2. The first question you should ask yourself is “is 78% low, or high, or in-between?” Maher wants us to believe that the number is “high”, but is it really? Let’s look for some baseline data with which to compare the 78% statistic. The obvious comparison is the incidence of “overweight” in the general US population. Only when we find this data point will we be able to assess whether 78% is a high (or low) number. What do we find? Let’s go back to the US CDC website and we find this: “Percent of adults aged 20 and over with overweight, including obesity: 73.6% (2017-2018).”
So, what can we conclude? The proportion of USA adults dying from COVID-19 who are “overweight” (78%) is almost the same proportion of the USA adult population that is “overweight (73.6%).” Put another way, the likelihood of randomly selecting a USA adult who is overweight versus randomly selecting one who is not overweight is 73.6/26.4≈3.29. If one were to randomly select an adult who died from COVID-19, one would be 78/22≈3.55 times more likely to select an overweight person than a non-overweight person. Ultimately, in the USA at least, as of the end of April overweight adults are dying from COVID-19 at a rate that is about equal to their proportion in the general adult US population.
We can show this graphically via a pie chart. For many reasons, the use of pie charts is generally frowned upon. But, in this case, where there are only two categories—overweight, and non-overweight—pie charts are a useful visualization tool, which allows for easy visual comparison. Here are the pie charts, and the R code that produced them below:
Created by: Josip Dasović
We can clearly see that the proportion of COVID-19 deaths from each cohort—overweight, non-overweight—is almost the same as the proportion of each cohort in the general USA adult population. So, a bit of critical analysis of Maher’s claim shows that he is not making the strong case that he believes he is.
# Here is the required data frame
covid.df <- data.frame("ADULT"=rep(c("Overweight", "Non-overweight"),2),
"Percentage"=c(0.736,0.264,0.78,0.22),
"Type"=rep(c("Total Adult Population","COVID-19 Deaths"),each=2))
library(ggplot2)
# Now the code for side-by-side pie charts:
ggpie.covid <- ggplot(covid.df, aes(x="", y=Percentage, group=ADULT, fill=ADULT, )) +
geom_bar(width = 1, stat = "identity") +
scale_fill_manual(values=c("#33B2CC","#D71920"),name ="ADULT CATEGORY") +
labs(x="", y="", title="Percentage of USA Adults who are Overweight",
subtitle="(versus percentage of USA COVID-19 deaths who were overweight)") +
coord_polar("y", start=0) + facet_wrap(~ Type) +
theme(axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank(),
plot.title = element_text(hjust = 0.5, size=16, face="bold"),
plot.subtitle = element_text(hjust=0.5, face="bold"))
ggsave(filename="covid19overweight.png", plot=ggpie.covid, height=5, width=8)
As part of a project to assess the influence, or impact, of Canadian provincial government ruling ideologies on provincial economic performance I have created a time-series cross-section summary of my party ideology variable across provinces over time. A time-series cross-section research design is one in which there is variation across space (cross-section) and also over time. The time units can literally be anything although in comparative politics they are often years. The cross-section part can be countries, cities, individuals, states, or (in my case) provinces. Here is the snippet of the data structure in my dataset (data frame in R):
canparty.df[1:20,c(2:4,23)]
Year Region Pol.Party party.ideology
1981 Alberta Progressive Conservative Party 1
1981 British Columbia Social Credit Party 1
1981 Manitoba Progressive Conservative Party 1
1981 New Brunswick Progressive Conservative Party 1
1981 Newfoundland and Labrador Progressive Conservative Party 1
1981 Nova Scotia Progressive Conservative Party 1
1981 Ontario Progressive Conservative Party 1
1981 Prince Edward Island Progressive Conservative Party 1
1981 Quebec Parti Quebecois 0
1981 Saskatchewan New Democratic Party -1
1982 Alberta Progressive Conservative Party 1
1982 British Columbia Social Credit Party 1
1982 Manitoba New Democratic Party -1
1982 New Brunswick Progressive Conservative Party 1
1982 Newfoundland and Labrador Progressive Conservative Party 1
1982 Nova Scotia Progressive Conservative Party 1
1982 Ontario Progressive Conservative Party 1
1982 Prince Edward Island Progressive Conservative Party 1
1982 Quebec Parti Quebecois 0
1982 Saskatchewan Progressive Conservative Party 1
To get the plot picture below, we use the R code at the bottom of this post. But a couple of notes: first, the year data are not in true date format. Rather, they are in periods, which I have conveniently labelled years. In other words, what is important for the analysis that I will do (generalized synthetic control method) is to periodize the data. Second, because elections occur at any point during the year, I have had to make a decision as to which party is coded as having been in government that year.
Since my main goal is to assess economic performance, and because economic policies take time to be passed, and to implement, I made the decision to use June 30th as a cutoff point. If a party was elected prior to that date, it is coded as having governed the province in that whole year. If the election was held on July 1st (or after), then the incumbent party is coded as having governed the province the year of the election and the new government is coded as having started its mandate the following year.
Here’s the plot, and the R code below:
library(gsynth)
library(panelView)
library(ggplot2)
ggpanel1 <- panelView(Prop.seats.gov ~ party.ideology + Prov.GDP.Cap, data = canparty.df,
index = c("Region", "Year"), main = "Provincial Ruling Party Ideology",
legend.labs = c("Left", "Centre", "Right"), col=c("orange", "red", "blue"),
axis.lab.gap = c(2,0), xlab="", ylab="")
## I've used Prop.seats.gov and Prov.GDP.Cap b/c they are two
## of my IVs, but any other IVs could have been used to
## create the plot. The important part is the party.ideology
## variable and the two index variables--Region (province) ## and Year.
## Save the plot as a .png file
ggsave(filename="ProvRulingParty.png", plot=ggpanel1, height=8,width=7)
My most recent post in this series analyzed data related to the federal equalization program in Canada using a lollipop plot made with ggplot2 in R. The data that I chose to visualize—annual nominal dollar receipts by province—give the reader the impression that over the last five-plus decades the province of Quebec (QC) is the main recipient (by far) of these federal transfer funds. While this may be true, the plot also misrepresents the nature of these financial flows from the federal government to the provinces. The data does not take into account the wide variation in populations amongst the 10 provinces. For example, Prince Edward Island (PEI) as of 2019 has a population of about 156,000 residents, while Quebec has a population of approximately 8.5 million, or about 55 times as much as PEI. That is to say a better way of representing the provincial receipt of equalization funds is to calculate the annual per capita (i.e., for every resident) value, rather than a provincial total.
For the lollipop chart below, I’ve not only calculated an annual per-capita measure of the amount of money received by province, I’ve also controlled for inflation, understanding that a dollar in 1960 was worth a lot more (and could be used to buy many more resources) in 1960 than today. Using Canadian GDP deflator data compiled by the St. Louis Federal Reserve, I’ve created plotting variable—annual real per-capita federal equalization receipts by province, with a base year of 2014. Here, we see that the message of the plot is no longer Quebec’s dominance but a story in which Canadians (regardless of where they live) are treated relatively equally. Of course, every year, Canadian in some provinces receive no equalization receipts.
There is likely no federal-provincial political issue that stokes more anger amongst Albertans (and is so misunderstood) as equalization payments (entitlements) from the Canadian federal to the country’s 10 provinces. Although some form of equalization has always been a part of the federal government’s policy arsenal, the current equalization program was initiated in the late 1950s, with the goal of providing, or at least helping achieve an equal playing field across the country in terms of basic levels of public services. As Professor Trevor Tombe notes:
Regardless of where you live, we are committed (indeed, constitutionally committed) to ensure everyone has access to “reasonably comparable levels of public services at reasonably comparable levels of taxation.”
Finances of the Nation, Trevor Tombe
For more information about the equalization program read Tombe’s article and links he provides to other information. The most basic misunderstanding of the program is that while some provinces receive payments from the federal government (the ‘have-nots’) the other, more prosperous, provinces (the ‘haves’) are the source of these payments. You often hear the phrase “Alberta sends X $billion to Quebec every year!” That’s not the case. The funds are generated and distributed from federal revenues (mostly income tax) and disbursed from this same fund of resources. The ‘have’ provinces don’t “send money” to other provinces. The federal government collects tax revenue from all individuals and if a province has a higher proportion of high-earning workers than another, it will generally receive less back in money from the federal government than its workers send to Ottawa. (To reiterate, read Tombe for more about the particulars.)
Using data provided by the Government of Canada, I have decided to show the federal equalization outlays over time using what is called a lollipop chart. I could have used a bar chart, but I like the way the lollipop chart looks. Here’s the chart and the R code below:
If you are at all familiar with the politics and communication surrounding the global warming issue you’ll almost certainly have come across one of the most popular talking points among those who dismiss (“deny”) contemporary anthropogenic (human-caused) climate change (I’ll call them “climate deniers” henceforth). The claim goes something like this:
“If scientists can’t predict the weather a week from now, how in the world can climate scientists predict what the ‘weather’ [sic!] is going to be like 10, 20, or 50 years from now?”
Notably, the statement does possess a prima facie (i.e., “commonsensical”) claim to plausibility–most people would agree that it is easier (other things being equal) to make predictions about things are closer in time to the present than things that happen well into the future. We have a fairly good idea of the chances that the Vancouver Canucks will win at least half of their games for the remainder of the month of March 2021. We have much less knowledge of how likely the Canucks will be to win at least half their games in February 2022, February 2025, or February 2040.
Notwithstanding the preceding, the problem with this denialist argument is that it relies on a fundamental misunderstanding of the difference between climate and weather. Here is an extended excerpt from the US NOAA:
We hear about weather and climate all of the time. Most of us check the local weather forecast to plan our days. And climate change is certainly a “hot” topic in the news. There is, however, still a lot of confusion over the difference between the two.
Think about it this way: Climate is what you expect, weather is what you get.
Weather is what you see outside on any particular day. So, for example, it may be 75° degrees and sunny or it could be 20° degrees with heavy snow. That’s the weather.
Climate is the average of that weather. For example, you can expect snow in the Northeast [USA] in January or for it to be hot and humid in the Southeast [USA] in July. This is climate. The climate record also includes extreme values such as record high temperatures or record amounts of rainfall. If you’ve ever heard your local weather person say “today we hit a record high for this day,” she is talking about climate records.
So when we are talking about climate change, we are talking about changes in long-term averages of daily weather. In most places, weather can change from minute-to-minute, hour-to-hour, day-to-day, and season-to-season. Climate, however, is the average of weather over time and space.
The important message to take from this is that while the weather can be very unpredictable, even at time-horizons of only hours, or minutes, the climate (long-term averages of weather) is remarkably stable over time (assuming the absence of important exogenous events like major volcanic eruptions, for example).
Although weather forecasting has become more accurate over time with the advance of meteorological science, there is still a massive amount of randomness that affects weather models. The difference between a major snowstorm, or clear blue skies with sun, could literally be a slight difference in air pressure, or wind direction/speed, etc. But, once these daily, or hourly, deviations from the expected are averaged out over the course of a year, the global mean annual temperature is remarkably stable from year-to-year. And it is an unprecedentedly rapid increase in mean annual global temperatures over the last 250 years or so that is the source of climate scientists’ claims that the earth’s temperature is rising and, indeed, is currently higher than at any point since the beginning of human civilization some 10,000 years ago.
Although the temperature at any point and place on earth in a typical year can vary from as high as the mid-50s degrees Celsius to as low as the -80s degrees Celsius (a range of some 130 degrees Celsius) the difference in the global mean annual temperature between 2018 and 2019 was only 0.14 degrees Celsius. That incorporates all of the polar vortexes, droughts, etc., over the course of a year. That is remarkably stable. And it’s not a surprise that global mean annual temperatures tend to be stable, given the nature of the earth’s energy system, and the concept of earth’s energy budget.
In the same way that earth’s mean annual temperatures tend to be very stable (accompanied by dramatic inter-temporal and inter-spatial variation), we can see that the collective result of many repeated spins of a roulette wheel is analogously stable (with similarly dramatic between-spin variation).
A roulette wheel has 38 numbered slots–36 of which are split evenly between red slots and black slots–numbered from 1 through 36–and (in North America) two green slots which are numbered 0, and 00. It is impossible to determine with any level of accuracy the precise number that will turn up on any given spin of the roulette wheel. But, we know that for a standard North American roulette wheel, over time the number of black slots that turn up will be equal to the number of red slots that turn up, with the green slots turning up about 1/9 as often as either red or black. Thus, while we have no way of knowing exactly what the next spin of the roulette wheel will be (which is a good thing for the casino’s owners), we can accurately predict the “mean outcome” of thousands of spins, and get quite close to the actual results (which is also a good thing for the casino owners and the reason that they continue to offer the game to their clients).
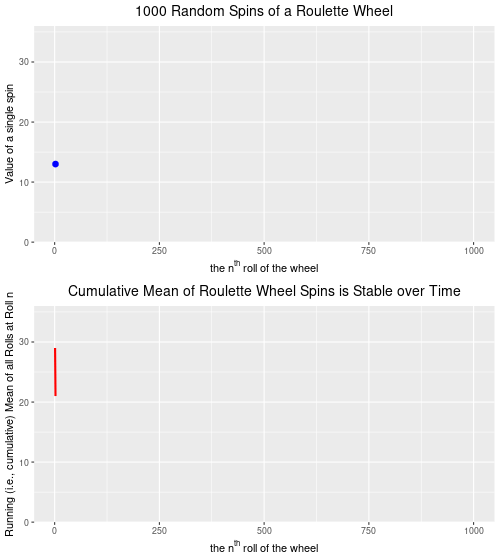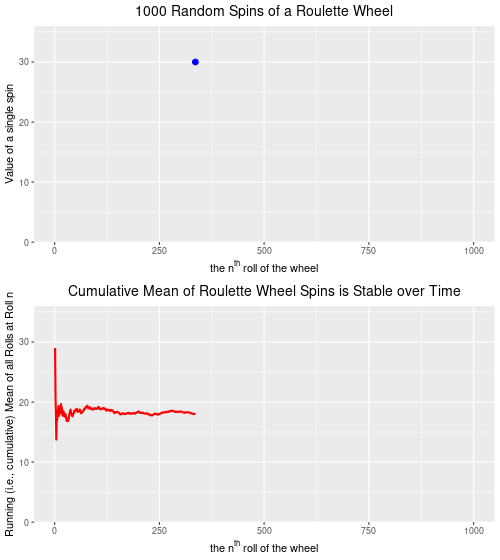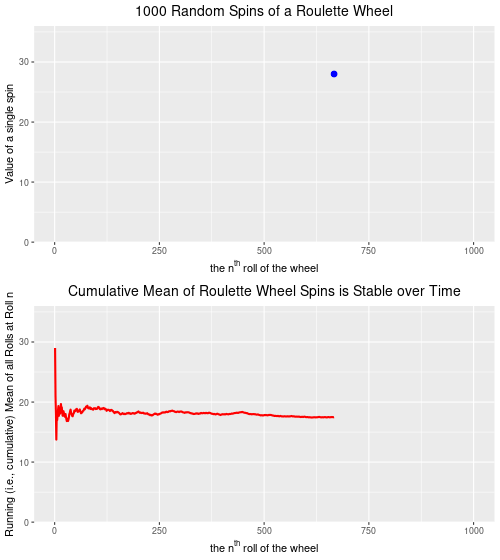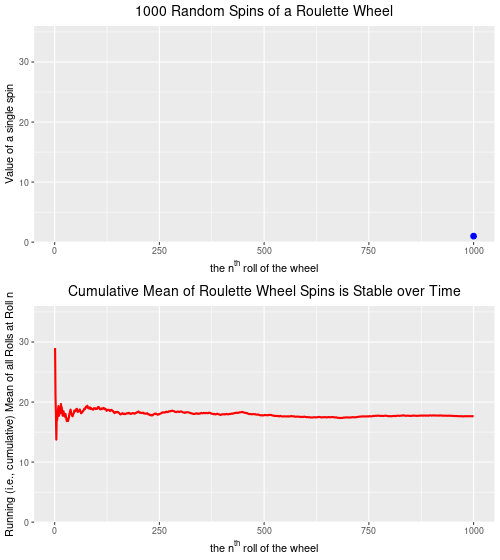
Below are two plots–the upper plot is an animated plot of each of 1000 simulated random spins of a roulette wheel. We can see that the value of each of the individual spins varies considerably–from a low of 0 to a high of 36. It is impossible to predict what the value of the next spin will be.
The lower plot, on the other hand is an animated plot, the line of which represents the cumulative (i.e. “running”) mean of 1000 random spins of a roulette wheel. We see that for the first few random rolls of the roulette wheel the cumulative mean is relatively unstable, but as the number of rolls increases the cumulative mean eventually settles down to a value that is very close to the ‘expected value’ (on a North Amercian roulette wheel) of 17.526. The expected value* is simply the sum of all of the individual values 0,0, 1 through 36 divided by the total number of slots, which is 38. Over time, as we spin and spin the roulette wheel, the values from spin-to-spin may be dramatically different. Over time, though, the mean value of these spins will converge on the expected value of 17.526. From the chart below, we see that this is the case.
Created by Josip Dasović
Completing the analogy to weather (and climate) prediction, on any given spin our ability to predict what the next spin of the roulette wheel will be is very low. [The analogy isn’t perfect because we are a bit more confident in our weather predictions given that the process is not completely random–it will be more likely to be cold and to snow in the winter, for example.] But, over time, we can predict with a high degree of accuracy that the mean of all spins will be very close to 17.526. So, our inability to predict short-term events accurately does not mean that we are not able to predict long-term events accurately. We can, and we do. In roulette, and for the climate as well.
TLDR: Just because a science can’t predict something short-term does not mean that it isn’t a science. Google quantum physics and randomness and you’ll understand what Einstein was referring to when he quipped that “God does not play dice.” Maybe she’s a roulette player instead?
Note: This is not the same as the expected dollar value of a bet given that casinos generate pay-off matrixes that are advantageous to themselves.
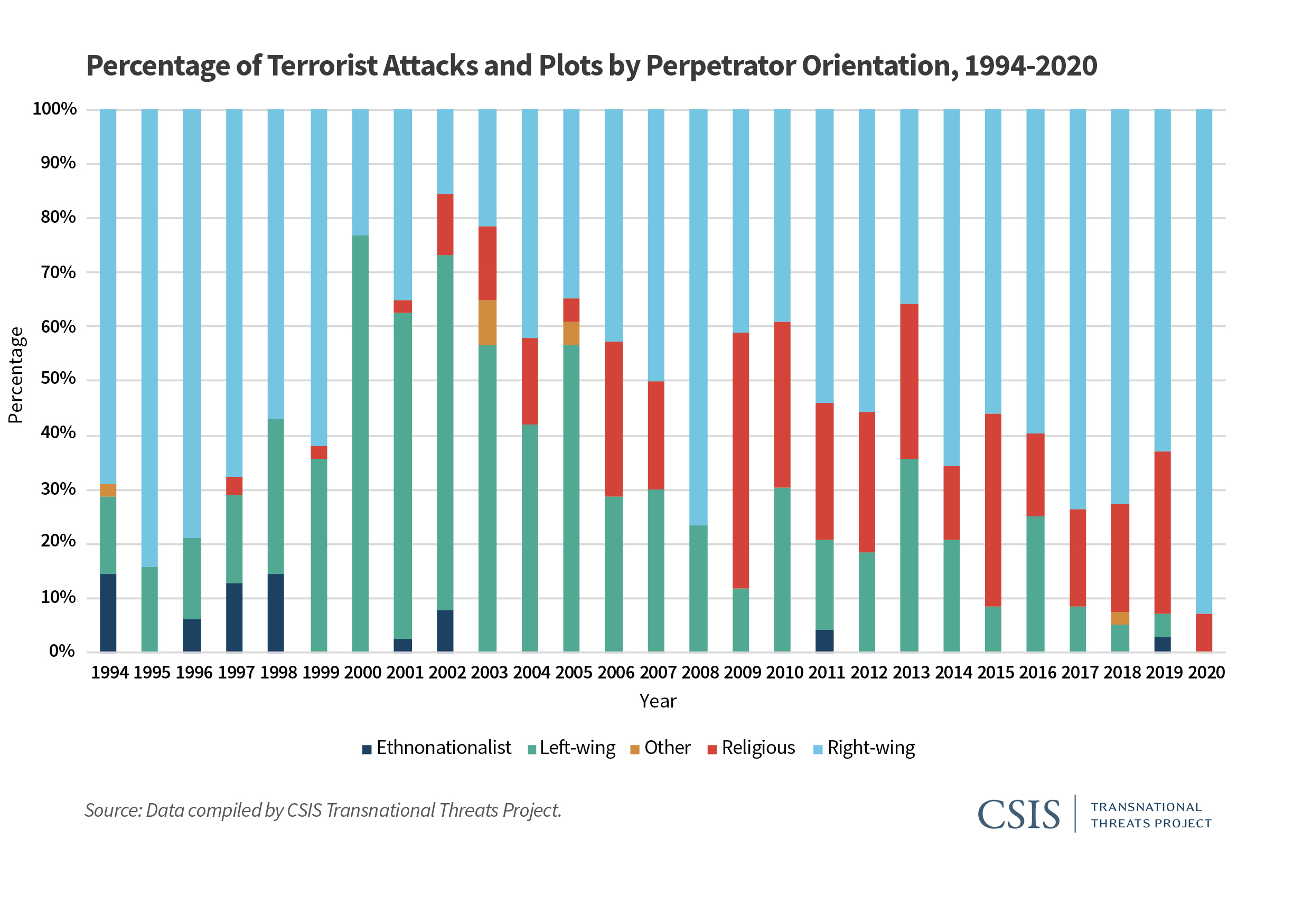
Stacked bar plots (charts) are a very useful data visualization type…when used correctly. In an otherwise excellent report on the “Escalating Terrorism Problem in the United States” from the Center for Strategic and International Studies, there is a problematic stacked bar chart (actually, a stacked percentage chart) that should have been replaced by a grouped bar chart (or something else). Here is the, in my opinion, problematic chart:
The reason I believe this chart is problematic is because the chart could potentially obscure the nature (and trend) of the underlying data. The chart above is consistent with any number of underlying data patterns. Just as an example, let’s look at 2019 and 2020. We have the following percentage breakdown over the two years:
Type of Violence
2019
2020
Ethnonationalist
3%
0%
Left-wing
4%
0%
Other
0%
0%
Religious
30%
7%
Right-wing
63%
93%
While it is obvious that ethnonationalist, and left-wing, violence have decreased (they are 0% in 2020), it is not clear whether right-wing and religious violence have increased, or decreased absolutely. Does right-wing violence in 2020 comprise 93% of 14 acts of terrorist violence? Or is it 93% of 200 acts of terrorist violence? We don’t know. To be fair to the authors of the report, they do provide a breakdown in absolute numbers later in the report. Still, I believe that a more appropriate use of a stacked bar/percentage chart is when the absolute number of instances is (relatively) static over the time/area of comparison.
Here’s an example from college football. The Pacific-12 conference has two divisions–North, and South. Every year each of the 6 teams in each division plays against 4 of the teams in the other division, for a total of 24 inter-divisional games every year. In addition, there is a PAC12 Championship Game, which pits the winner of each of the two divisions against each other at the end of the year. Therefore, there are 25 total inter-divisional PAC12 football games every year. A stacked percentage chart can be used to gauge the relative winning percentages of the two divisions against each other since the establishment of the PAC12 conference in 2011 (when Utah and Colorado were added).
Created by Josip Dasović
Here, each of the years refers to a total of 25 inter-divisional games. We can easily see the nature of the quality of the respective divisions by comparing the percentage of games won by each (over the other) between the years 2011 and 2019. We see that the North (which, by the way produced 8 of the 9 PAC12 champions during this period) has generally been stronger. In 6 of the 9 years, the North won a greater percentage of the inter-divisional games than did the South. And even in those years where the South won a greater percentage of the inter-divisional games, it wasn’t a much greater percentage.
So, use stacked percentage charts only when it is appropriate.
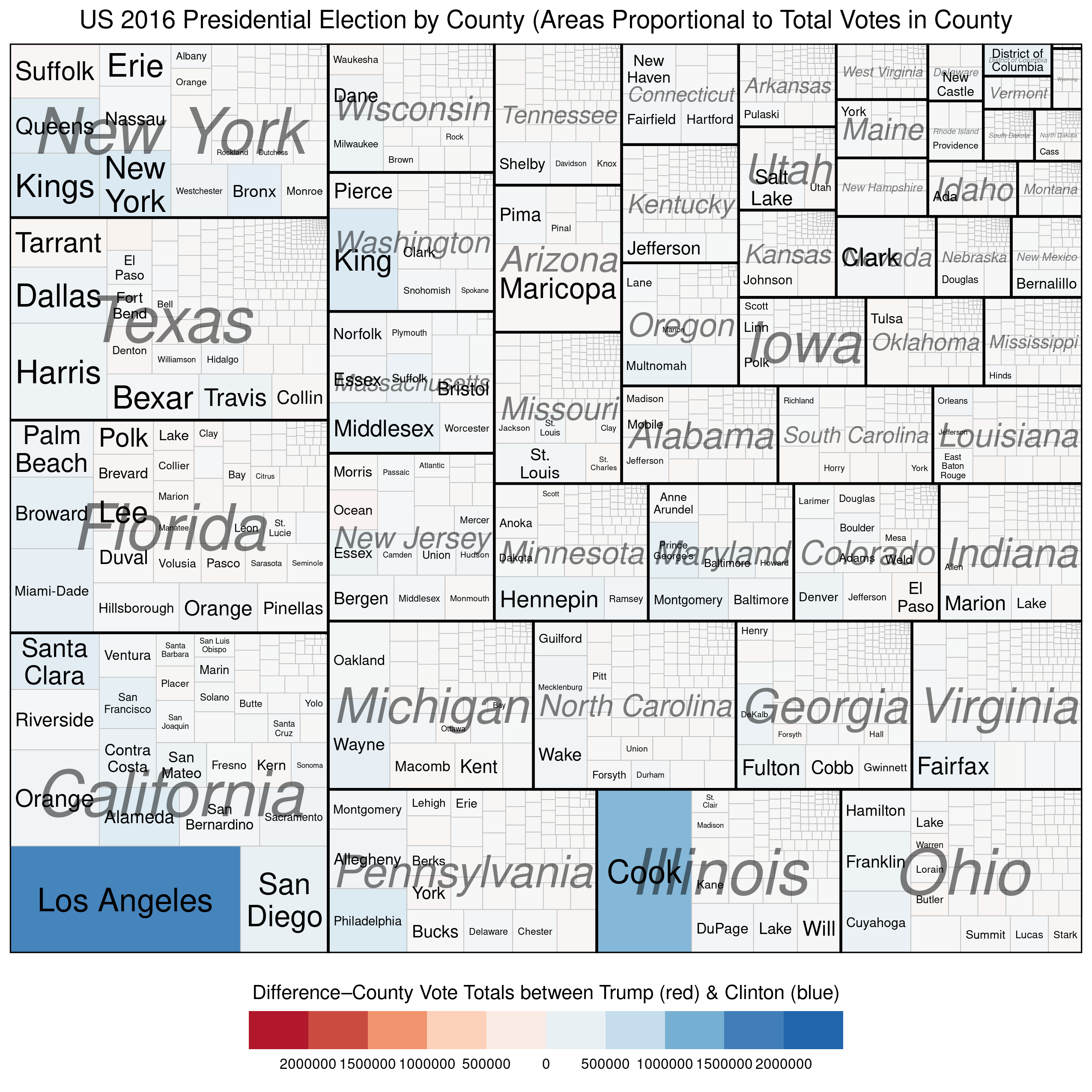
While we’re still waiting on the availability of official county-level results 2020 the 2020 US Presidential Elections*, I thought I’d create a treemap of the county-level results from the 2016 election. You may be thinking to yourself, “What is a treemap?”
Treemaps are ideal for displaying large amounts of hierarchically structured (tree-structured) data. The space in the visualization is split up into rectangles that are sized and ordered by a quantitative variable.
Treemaps, therefore, can help us visualize the relationships within our quantitative data in a unique, visually-pleasing, and meaningfully effective manner. Let’s see how with the example of the US 2016 Presidential Election.
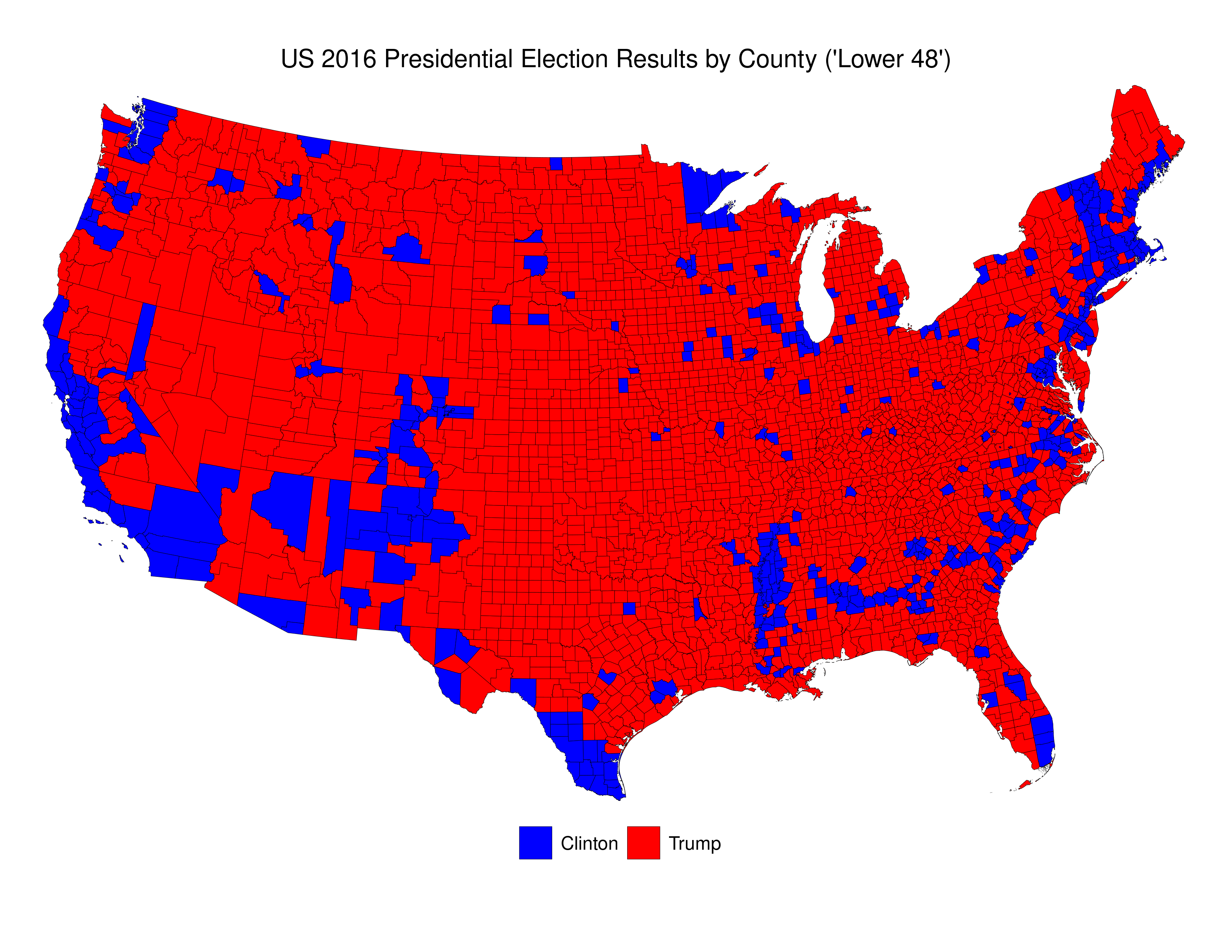
Here’s a picture of then newly-elected President Donald Trump looking at a map given to him by his advisers depicting the results of the 2016 election. This specific depiction of the results overstates the extent of the support across the USA for Trump in the 2016 election. As those in the know often say “land mass does not vote.” Indeed, if one were ignorant about US politics, and US political demography, looking at that map one would be most likely be perplexed were one told that the “blue” candidate actually won 3 million more votes than did the “red” candidate.
Here is my reproduction of these data\2013using publicly-available data from MIT Election Data and Science Lab, 2018, “County Presidential Election Returns 2000-2016”, https://doi.org/10.7910/DVN/VOQCHQ, Harvard Dataverse, V6, UNF:6:ZZe1xuZ5H2l4NUiSRcRf8Q== [fileUNF]. I’ve added the R-code at the end of this post.
We can see that the vast majority of counties are small, and that voters in these counties were more likely to have voted for Trump than for Clinton. Indeed, Clinton win fewer than 16% of all counties.
The problem with this map is that it essentially dichotomizes quantitative data into qualitative data. To be precise, the decision whether to colour a county blue or red is made simply on the basis of whether, of those who voted, more voted for Trump, or for Clinton. If a county voted 51-50 for Trump, it gets a red colour. If a county voted 1,000,000-100,000 for Clinton it gets coloured blue. And, to make things even more confusing, the total of red that each county receives is related ONLY to country land area, and doesn’t take account of the number of voters.
As is the case in many parts of the world today, the US is increasingly split demographically\u2013with those living in rural areas (and suburbs/exurbs) voting for the conservative parties (Republican) and those in the urban areas voting for liberal parties (Democratic). We see this clearly in the map above. The problem with US counties is that they are not uniform either in terms of their land area, or their population. There are apartment buildings in New York City and Los Angeles that have more residents than some counties.
We can use treemaps to more “accurately” depict electoral outcomes. By accurately, I mean that the visual representation of the data more closely reflects how many voted for each candidate (party).
The first example below represents the vote at the county level and describes two quantitative variables. The size of each rectangle represents the total number of voters in each county\u2013the larger the rectangle the greater the numbers of voters in that county. The second variable, which is mapped using the colour scale, represents the difference\u2013in raw vote totals between the two candidates. Reddish shades denote a county that was won by Trump, while bluish shades represent counties won by Clinton.
There are a couple of things to notice. First, the wide disparity in the total number of voters across the counties. Second, we see that most of the counties have shades that are only very lightly blue (or red) and look mostly white. This is because the range on the variable must be so expansive in order to include outliers like Los Angeles and Cook Counties. Thus, in the vast majority of US counties the raw vote total differences between Trump’s totals and Clinton’s totals are in the 1000s range. This is why Trump was able to win more than 84% of US counties and still lose the popular vote by more than 3 million.
Our next (and final) treemap is similar to the one above except that the scale for the colouring is not the raw vote difference between Trump and Clinton in each county, but the percentage-point differential in vote between the two candidates.
We see much more red and blue in this map because the scale is confined to 100% Trump win to 100% Clinton win. Notice the striking disparity in where the blue and red colours, respectively, are found. The reddish shades dominate in small-population counties (in the top-right corner of each state subgroup), while the bluish shades dominate in large-population counties (in the bottom-left corners of each state subgroup). Finally, the larger (greater population) counties tend be be much smaller geographically than the less-populous counties, which is why the map on Trump’s desk looks like it does.
R Code for treemaps: (this is vote the “total vote” variable. Replace that variable with a “percentage-vote” variable–with appropriate limits and breaks (-100,100) because you are now working with percentages).
* The electoral process that determines who becomes president of the United States is complicated. In effect, it is a series of elections that are run by individual states, and not a single federally-run election like it is in most presidential systems.













You must be logged in to post a comment.