
In teaching research methods courses in the past, a tool that I’ve used to help students understand the nuances of policy analysis is to ask them to assess a claim such as:
In the last 12 months, statistics show that the government of Upper Slovobia’s policy measures have contributed to limiting the infollcillation of ramakidine to 34%.
The point of this exercise is two-fold: 1) to teach them that the concepts we use in social science are almost always socially constructed, and we should first understand the concept—how it is defined, measured, and used—before moving on to the next step of policy analysis. When the concepts used—in this case, infollcillation and ramakidine—are ones nobody has every heard of (because I invented them), step 1 becomes obvious. How are we to assess whether a policy was responsible for something when we have zero idea what that something even means? Often, though, because the concept is a familar one—homelessness, polarization, violence—we often skip right past this step and focus on the next step (assessing the data).
2) The second point of the exercise is to help students understand that assessing the data (in this case, the 34% number) can not be done adequately without context. Is 34% an outcome that was expected? How does that number compare to previous years and the situation under previous governments, or the situation with similar governments in neighbouring countries? (The final step in the policy analysis would be to set up an adequate research design that would determine the extent to which the outcome was attributable to policies implemented by the South Slovobian government.)
If there is a “takeaway” message from the above, it is that whenever one hears a numerical claim being made, first ask yourself questions about the claim that fill in the context, and only then proceed to evaluate the claim.
Let’s have a look at how this works, using a real-life example. During a recent episode of Real Time, host Bill Maher used his New Rules segment to admonish the public (especially its more left-wing members) for overestimating the danger to US society of the COVID-19 virus. He punctuated his point by using the following statistical claim:
Maher not only claims that the statistical fact that 78% of COVID-19-caused fatalities in the USA have been from those who were assessed to have been “overweight” means that the virus is not nearly as dangerous to the general USA public as has been portrayed, but he also believes that political correctness run amok is the reason that raising this issue (which Americans are dying, and why) in public is verboten. We’ll leave aside the latter claim and focus on the statistic—78% of those who died from COVID-19 were overweight.
Does the fact that more than 3-in-4 COVID-19 deaths in the USA were individuals assessed to have been overweight mean that the danger to the general public from the virus has been overhyped? Maher wants you to believe that the answer to this question is an emphatic ‘yes!’ But is it?
Whenever you are presented with such a claim follow the steps above. In this case, that means 1) understand what is meant by “overweight” and 2) compare the statistical claim to some sort of baseline.
The first is relatively easy—the US CDC has a standard definition for “overweight”, which can be found here: https://www.cdc.gov/obesity/adult/defining.html. Assuming that the definition is applied consistently across the whole of the USA, we can move on to step 2. The first question you should ask yourself is “is 78% low, or high, or in-between?” Maher wants us to believe that the number is “high”, but is it really? Let’s look for some baseline data with which to compare the 78% statistic. The obvious comparison is the incidence of “overweight” in the general US population. Only when we find this data point will we be able to assess whether 78% is a high (or low) number. What do we find? Let’s go back to the US CDC website and we find this: “Percent of adults aged 20 and over with overweight, including obesity: 73.6% (2017-2018).”
So, what can we conclude? The proportion of USA adults dying from COVID-19 who are “overweight” (78%) is almost the same proportion of the USA adult population that is “overweight (73.6%).” Put another way, the likelihood of randomly selecting a USA adult who is overweight versus randomly selecting one who is not overweight is 73.6/26.4≈3.29. If one were to randomly select an adult who died from COVID-19, one would be 78/22≈3.55 times more likely to select an overweight person than a non-overweight person. Ultimately, in the USA at least, as of the end of April overweight adults are dying from COVID-19 at a rate that is about equal to their proportion in the general adult US population.
We can show this graphically via a pie chart. For many reasons, the use of pie charts is generally frowned upon. But, in this case, where there are only two categories—overweight, and non-overweight—pie charts are a useful visualization tool, which allows for easy visual comparison. Here are the pie charts, and the R code that produced them below:
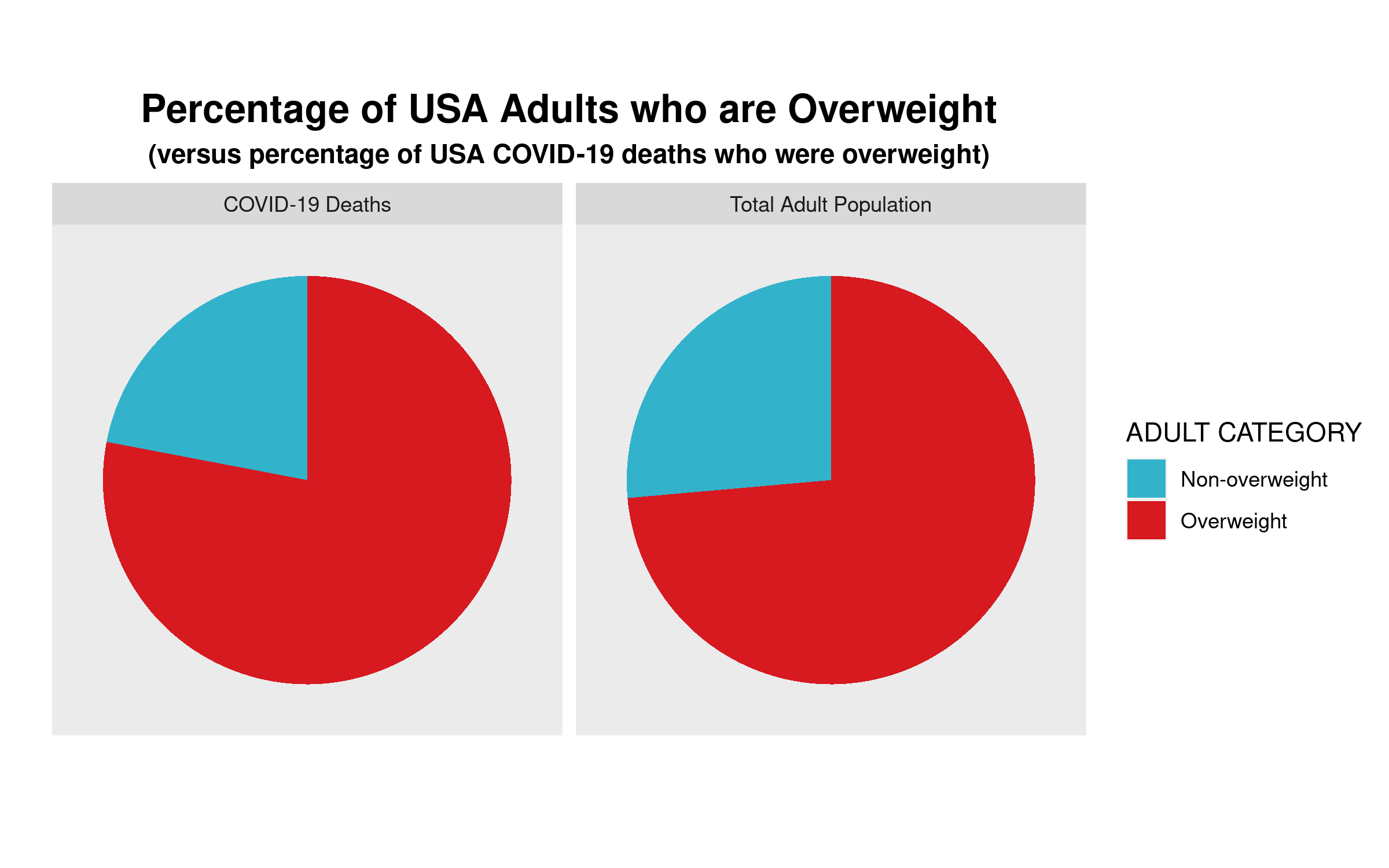
We can clearly see that the proportion of COVID-19 deaths from each cohort—overweight, non-overweight—is almost the same as the proportion of each cohort in the general USA adult population. So, a bit of critical analysis of Maher’s claim shows that he is not making the strong case that he believes he is.
# Here is the required data frame
covid.df <- data.frame("ADULT"=rep(c("Overweight", "Non-overweight"),2),
"Percentage"=c(0.736,0.264,0.78,0.22),
"Type"=rep(c("Total Adult Population","COVID-19 Deaths"),each=2))
library(ggplot2)
# Now the code for side-by-side pie charts:
ggpie.covid <- ggplot(covid.df, aes(x="", y=Percentage, group=ADULT, fill=ADULT, )) +
geom_bar(width = 1, stat = "identity") +
scale_fill_manual(values=c("#33B2CC","#D71920"),name ="ADULT CATEGORY") +
labs(x="", y="", title="Percentage of USA Adults who are Overweight",
subtitle="(versus percentage of USA COVID-19 deaths who were overweight)") +
coord_polar("y", start=0) + facet_wrap(~ Type) +
theme(axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank(),
plot.title = element_text(hjust = 0.5, size=16, face="bold"),
plot.subtitle = element_text(hjust=0.5, face="bold"))
ggsave(filename="covid19overweight.png", plot=ggpie.covid, height=5, width=8)

You must be logged in to post a comment.